by polyrand on 6/11/25, 1:38 PM with 23 comments
by smpretzer on 6/11/25, 4:30 PM
My only headache was that I was invoking it from python, and it does not have bindings, so I had to write a custom wrapper to call out to it. I am not sure of the difficulty of adding native support for Python, but I assume its not worth the squeeze and just calling out to a subprocess will work for most user's needs.
by therealmarv on 6/11/25, 2:38 PM
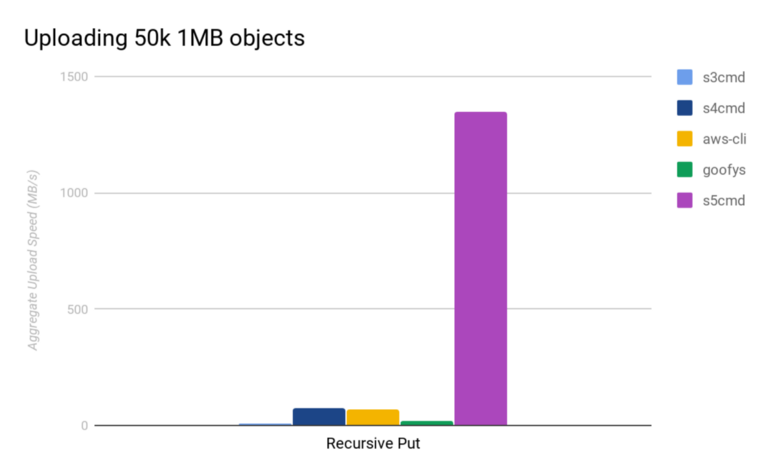
https://raw.githubusercontent.com/peak/s5cmd/master/doc/benc...
I've implemented at work once a rudimentary parallel uploading of many small files to S3 in Python and with boto3 (was not allowed to use a third party library or tool at that time) because it's soooo slow to upload many small files to S3. It really takes ages and even if you just upload 8 small files in parallel it makes a huge difference.
by rsync on 6/11/25, 2:59 PM
ssh user@rsync.net s5cmd
Password:
NAME:
s5cmd - Blazing fast S3 and local filesystem execution tool
USAGE:
s5cmd [global options] command [command options] [arguments...]
by Galanwe on 6/11/25, 2:53 PM
I'm surprised by these claims. I have worked pretty intimately with S3 for almost 10 years now, developed high performance tools to retrieve data from it, as well as used dedicated third party tools for performant file download tailored for S3.
My experience is that individual S3 connections are capped over the board at ~80MB/s, and the throughput of 1 file is capped at 1.6GB/s (at least per ec2 instance). At least I have never managed myself nor seen any tool capable of going beyond that.
My understanding is then that this benchmark's claims of 4.3GB/s are across multiple files, but then it would be rather meaningless, as it's free concurrency basically.
by quodlibetor on 6/11/25, 3:27 PM
It supports glob patterns like so, and will do smart filtering at every stage possible: */2025-0[45]-*/user*/*/object.txt
I haven't done real benchmarks, but it's parallel enough to hit s3 parallel request limits/file system open file limits when downloading.*
by BlackLotus89 on 6/11/25, 3:52 PM
For s3 mounts I would use geesefs.
Have to later take a look at s5cmd as well...
by nodesocket on 6/11/25, 2:27 PM
by StackTopherFlow on 6/11/25, 3:22 PM
by remram on 6/11/25, 5:37 PM
{kind=link}