by mofosyne on 5/31/25, 7:20 AM with 77 comments
by pastage on 6/3/25, 8:19 AM
I have seen people do ceramics where information was stacked in layers and had to be destroyed to extract. The ultimate form of shifting media to preserve and read information. I guess that could done with better resolution with 3D printed Zirconia (0.1 mm³ blobs) so 1Mb /cm³
Edit: this idea of a cold storage is from Footfall by Niven and Pournelle, where information was stored on monoliths where layers could be incrementally extracted with tools documented on the above layers. i.e. start with 0.1 bit per m² and go down, done with the hand wavy handling of practical problems in science fiction.
[1] https://www.bookandsword.com/2016/10/29/the-information-dens...
by tocs3 on 5/31/25, 1:51 PM
The biggest advantage of character-based encodings is that they can be decoded by humans (as opposed to dot-based encodings), which means that you don’t need a camera or a scanner to recover the data.
This is an interesting point. In our post apocalyptic future scholars will be using their quills to translate archives of these (in my imagination anyway). Of course they would have to translate into binary and then into human chars.
I can imaging they will be sad they cannot listen to the mp3's.
Adding color allows on to code more information per dot (3x more with three colors).
Is this right? Wouldn't it be base-3 encoding? Three bits of binary can count to 8. Three trits of base three can count to 27. Color has all sorts of disadvantages but maybe a much greater payoff (unless I m mistaken).
by benhurmarcel on 6/3/25, 12:53 PM
It has shown to be an issue for including data, or spreadsheets. Most colleagues just print Excel files to a PDF that gets appended, but while it complies with the regulation it's basically unusable as-is.
by rickcarlino on 6/3/25, 3:50 AM
by lifthrasiir on 6/3/25, 8:38 AM
For this reason, paper is at best useful as a bootstrapping mechanism, which would allow readers to construct a mechanism to read more densely encoded data. My best guess is that the main storage of information in this case would likely be microfilms, which should be at least 100x dense than the ideal paper data storage. Higher density allows for using less dense encodings to aid readers. And as far as I know microfilms are no harder to preserve than papers.
by account-5 on 6/3/25, 8:07 AM
You could encode data in monolithic structures this way. They'd last longer than paper and given future generations lots of confusion trying to figure out the meaning.
by 6510 on 6/3/25, 1:01 PM
by ryukoposting on 6/3/25, 11:49 AM
https://youtu.be/mIGotStRCkA?si=toG5xeLMZzjIGTxC
It's more like a long, linear barcode, but still. More often, they put the source code in the magazine and you'd just type it into your machine.
by mk_stjames on 6/3/25, 7:48 PM
I find it interesting that, if you were print 4 sheets double sided you would have roughly the same amount of information stored as a 720kb 5 1/4" floppy disk and if you cut and folded it would take up roughly the same size and weight.
by bn-l on 6/3/25, 11:35 AM
by zvr on 6/3/25, 8:30 AM
I am not sure why, for character-based encodings, they used a general-purpose font (Inconsolata) rather than one that is specifically made for OCR -- and how this would have made it better.
Going further, if you only print a limited alphabet (16, 32 or 39 symbols) why not use a specialized font with only these characters? The final step is to use a bitmap "font" that simply shows different character values as different bit patterns.
by pmontra on 6/3/25, 7:26 AM
by calrain on 6/3/25, 8:10 AM
I saw some work a while ago of storing SQL extracted table data as an image, and always thought that with good compression and a good printer, you could make paper copies.
by talles on 6/3/25, 4:27 PM
by eimrine on 5/31/25, 7:40 AM
I will try to remove dust from my A4 scanner and try to read that MP3 from printed medium, seems a bit insane to store multimedia in a paper but who needs to store it without proven ability to read. My printers love to mess with ink (especially ones with pirate-refilled cartridge) so I do not really believe this is practically at maximum resolution.
by Hyperlisk on 6/3/25, 2:37 PM
by c0nsumer on 6/3/25, 6:47 PM
by bob1029 on 6/3/25, 7:14 AM
I've seen these barcodes scan accurately off dingy plastic cards using webcams.
The information level per symbol is not great (about 1kb), but the error correction and physical layout work really well.
by mihaigalos on 6/3/25, 1:59 PM
by makeworld on 6/3/25, 4:15 AM
by slaymaker1907 on 6/3/25, 7:26 PM
by blueboo on 6/3/25, 9:43 AM
by kragen on 6/3/25, 12:21 PM
It's probably worth mentioning https://github.com/za3k/qr-backup/ which is tested in practice rather than merely theoretical. It doesn't achieve very high density, though.
The theoretical information capacity of an uncoated 600dpi laser-printed page ought to be close to 600×600 bits per square inch, 23.6×23.6 bits per square millimeter in modern units. This is 33.7 megabits per US letter page or 34.8 megabits per A4 page. The bit error rate of a laser printer is quite low, under 1%, and the margins are maybe another 5% at most. So modest ECC ought to be able to deliver most of that channel capacity in practice. QR codes and OCR apparently don't come close.
As an exercise, 13 years ago, I designed a proportional 1-bit-deep pixel font for printable ASCII, based on Janne Kujala's work, that averages about 3½×6 pixels. This is about 20 bits per character, so a letter-sized page should hold almost a megabyte of human-readable ASCII text. I generated the King James Bible in it at 600dpi. It comes to about four pages. Printed out in a half-assed way at double size (300dpi) on a 600dpi printer, you can read it pretty easily with a good magnifying glass. I have not yet been able to get an even partly readable printout at full resolution. If someone else tries it, I'm interested in hearing your results.
http://canonical.org/~kragen/bible-columns.png (warning, 93+-megapixel image, 4866×19254)
http://canonical.org/~kragen/bible-columns-320x200.png (small excerpt from the above)
http://canonical.org/~kragen/sw/netbook-misc-devel/6-pixel-1... (the font as a 374×7 image)
http://canonical.org/~kragen/sw/netbook-misc-devel/propfontr... (the image generation program I regret having written in Python because it won't run in current Python)
http://canonical.org/~kragen/sw/netbook-misc-devel/bible-pg1... (test input text, public domain everywhere except the UK)
by KWxIUElW8Xt0tD9 on 6/3/25, 11:00 AM
by superpupervlad on 6/3/25, 4:46 PM
by vubecnevim on 6/3/25, 7:11 AM
by slowhadoken on 6/3/25, 5:22 PM
by welder on 6/3/25, 12:23 PM
by tiahura on 6/3/25, 1:12 PM
by pknerd on 6/3/25, 4:26 PM
by pknerd on 6/3/25, 4:26 PM
by dsign on 6/3/25, 8:11 PM
by drsopp on 6/3/25, 6:05 AM
{kind=link}
{kind=link}
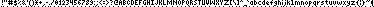{kind=link}