by Davidbrcz on 3/17/24, 10:15 AM with 129 comments
by klik99 on 3/17/24, 1:33 PM
by nebula8804 on 3/17/24, 11:23 AM
If this gets really good, maybe we can dream of having a fully de-obfuscated and open source life. All the layers of binary blobs in a PC can finally be decoded. All the drivers can be open. Why not do the OS as well! We don't have to settle for Linux, we can bring back Windows XP and back port modern security and app compatibility into the OS and Microsoft can keep their Windows 11 junk...at least one can dream! :D
by madisonmay on 3/17/24, 1:21 PM
by YeGoblynQueenne on 3/17/24, 9:42 PM
https://raw.githubusercontent.com/albertan017/LLM4Decompile/...
To clarify:
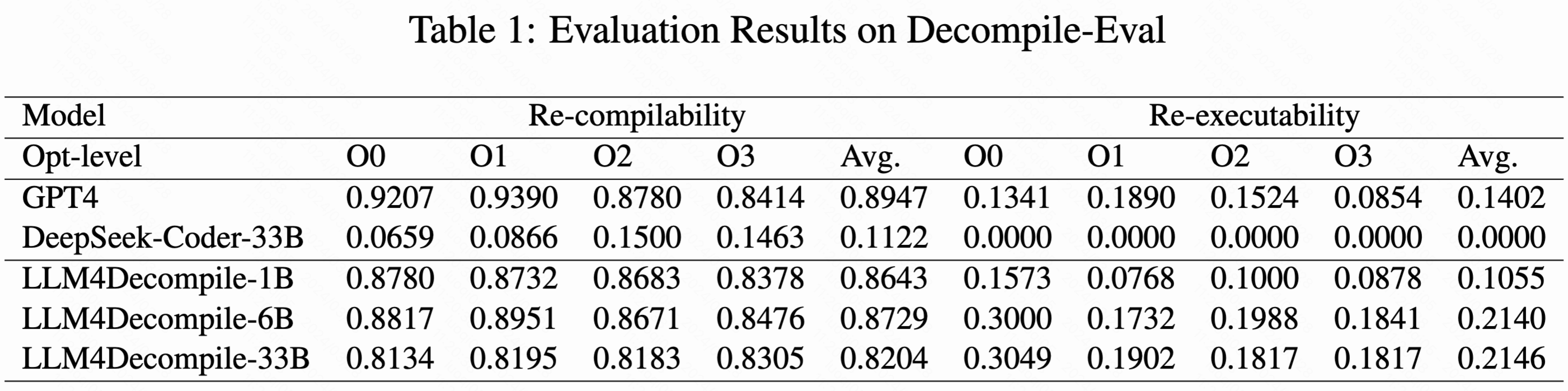
>> Re-executability provides this critical measure of semantic correctness. By re-compiling the decompiled output and running the test cases, we assess if the decompilation preserved the program logic and behavior. Together, re-compilability and re-executability indicate syntax recovery and semantic preservation - both essential for usable and robust decompilation.
by a2code on 3/17/24, 12:53 PM
What is unclear to me is: why did the authors fine-tune the DeepSeek-Coder model? Can you train an LLM from zero with a similar dataset? How big does the LLM need to be? Can it run locally?
by kukas on 3/17/24, 11:53 AM
by dwrodri on 3/18/24, 9:01 PM
A really good "stop-gap" approach would be to build a decompilation pipeline using Ghidra in headless mode and then combine the strict syntax correctness of a decompiler with the "intuition/system 1 skills" of an LLM. My inspiration for this setup comes from two recent advancements, both shared here on HN:
1. AlphaGeometry: The Decompiler and the LLM should complement each other, covering each other's weaknesses. https://deepmind.google/discover/blog/alphageometry-an-olymp...
2. AICI: We need a better way of "hacking" on top of these models, and being able to use something like AICI as the "glue" to coordinate the generation of C source. I don't really want the weights of my LLM to be used to generate syntactically correct C source, I want the LLM to think in terms of variable names, "snippet patterns" and architectural choices while other tools (Ghidra, LLVM) worry about the rest. https://github.com/microsoft/aici
Obviously this is all hand-wavey armchair commentary from a former grad student who just thinks this stuff is cool. Huge props to these researchers for diving into this. I know the authors already mentioned incorporating Ghidra into their future work, so I know they're on the right track.
by potatoman22 on 3/17/24, 11:03 AM
I'm also curious about how this compares to non-LLM solutions.
by AndrewKemendo on 3/17/24, 4:00 PM
In which case that means fully complete code can live in the “latent space” but is distributed as probabilities
Or perhaps more likely would it be replicating the logic only, which can then be translated into the target language
I would guess that any binary that requires a non-deterministic input (key, hash etc…) to compile would break this
Fascinating
by kken on 3/17/24, 11:13 AM
by maCDzP on 3/17/24, 11:06 AM
by sinuhe69 on 3/17/24, 6:23 PM
by mahaloz on 3/17/24, 8:08 PM
by saagarjha on 3/18/24, 2:11 AM
A couple people here have suggested that the generated decompilation should match the source code exactly, which is a challenging thing to achieve and still hotly debated on whether it is a good metric or not. But the results here show that we’re starting to barely get past the “does it produce code” stage and move towards “does it produce code that looks vaguely correct” status but we’re definitely not there yet. Future steps of “is this a useful tool to drive decompilation” and “does this do better than state of the art” and “is this perfect at decompiling things” are still a long ways away. So it’s good to look at as a negative result as this area continues to attract new interest.
by jagrsw on 3/17/24, 12:35 PM
Searching for vulns and producing patches in source code is a bit problematic, as the databases of vulnerable source code examples and their corresponding patches are neither well-structured nor comprehensive, and sometimes very, very specific to the analyzed code (for higher abstraction type of problems). So, it's not easy to train something usable beyond standard mem safety problems and use of unsafe APIs.
The area of fuzzing is somewhat messy, with sporadic efforts undertaken here and there, but it also requires a lot of preparatory work, and the results might not be groundbreaking unless we reach a point where we can feed an ML model the entire source code of a project, allowing it to analyze and identify all bugs, producing fixes and providing offending inputs. i.e. not yet.
While decompilation is a fairly standard problem, it is possible to produce input-output pairs somewhat at will based on existing source code, using various compiler switches, CPU architectures, ABIs, obfuscations, syscall calling conventions. And train models on those input-output pairs (i.e. in reversed order).
by m3kw9 on 3/17/24, 4:05 PM
by mdaniel on 3/17/24, 6:02 PM
ed: seems they have this, too, which may value your submission: https://github.com/tenable/awesome-llm-cybersecurity-tools#a...
by dolmen on 3/18/24, 10:33 AM
It should be possible to tokenize directly from the binary.
by speedylight on 3/17/24, 6:52 PM
by Nuzzerino on 3/17/24, 11:36 PM
by ReptileMan on 3/17/24, 3:49 PM
by quantum_state on 3/17/24, 7:51 PM
by xvilka on 3/18/24, 5:34 AM
│ │ 0x140007e51 movsd qword [rdi + 0x50], xmm2
│ │ 0x140007e56 mov qword [rdi + 0x48], 0
│ │ 0x140007e5e call sym.rz_test.exe_ht_pp_free ; sym.rz_test.exe_ht_pp_free
│ │ 0x140007e63 movaps xmm7, xmmword [var_38h]
│ │ 0x140007e68 movaps xmm6, xmmword [var_28h]
│ │ 0x140007e6d mov rbp, qword [var_10h]
│ └─> 0x140007e72 add rsp, 0x48
│ 0x140007e76 pop r15
│ 0x140007e78 pop rdi
└ 0x140007e79 ret
0x140007e6d (set rbp (loadw 0 64 (+ (var rsp) (bv 64 0x68))))
0x140007e72 (seq (set op1 (var rsp)) (set op2 (bv 64 0x48)) (set sum (+ (var op1) (var op2))) (set rsp (var sum)) (set _result (var sum)) (set _popcnt (bv 8 0x0)) (set _val (cast 8 false (var _result))) (repeat (! (is_zero (var _val))) (seq (set _popcnt (+ (var _popcnt) (ite (lsb (var _val)) (bv 8 0x1) (bv 8 0x0)))) (set _val (>> (var _val) (bv 8 0x1) false)))) (set pf (is_zero (mod (var _popcnt) (bv 8 0x2)))) (set zf (is_zero (var _result))) (set sf (msb (var _result))) (set _result (var sum)) (set _x (var op1)) (set _y (var op2)) (set cf (|| (|| (&& (msb (var _x)) (msb (var _y))) (&& (! (msb (var _result))) (msb (var _y)))) (&& (msb (var _x)) (! (msb (var _result)))))) (set of (|| (&& (&& (! (msb (var _result))) (msb (var _x))) (msb (var _y))) (&& (&& (msb (var _result)) (! (msb (var _x)))) (! (msb (var _y)))))) (set af (|| (|| (&& (msb (cast 4 false (var _x))) (msb (cast 4 false (var _y)))) (&& (! (msb (cast 4 false (var _result)))) (msb (cast 4 false (var _y))))) (&& (msb (cast 4 false (var _x))) (! (msb (cast 4 false (var _result))))))))
0x140007e76 (seq (set r15 (cast 64 false (loadw 0 64 (+ (var rsp) (bv 64 0x0))))) (set rsp (+ (var rsp) (bv 64 0x8))))
0x140007e78 (seq (set rdi (loadw 0 64 (+ (var rsp) (bv 64 0x0)))) (set rsp (+ (var rsp) (bv 64 0x8))))
0x140007e79 (seq (set tgt (loadw 0 64 (+ (var rsp) (bv 64 0x0)))) (set rsp (+ (var rsp) (bv 64 0x8))) (jmp (var tgt)))
[2] https://rizin.re
by xorvoid on 3/17/24, 5:19 PM
All that said, I'm not a pessimist on this idea. I think it has pretty great promise as a technique for general reversing security analysis where the reversing is done mostly for "discovery" and "understanding" rather than for perfect semantic lifting to a high-level language. In that world, you can afford to develop "hypotheses" and then drill down to validate if you think you've discovered something big.
Compiling and testing the resulting decompilation is a great idea. I do that as well. The limitation here is TEST SUITE. Some random binary doesn't typically come with a high-coverage test suite, so you have to develop your own acceptance criterion as you go along. In other words: write tests for a function whose computation you don't understand (ha). I suppose a form of static-analysis / symbolic-computation might be handy here (I haven't explored that). Here you're also beset with challenges of specifying which machine state changes are important and which are superfluous (e.g. is it okay if the x86 FLAGS register isn't modified in the decompiled version, probably yes, but sometimes no).
In my case I don't have access to the original compiler and even if I did, I'm not sure I could convince it to reproduce the same code. Maybe this is more feasible for more modern binaries where you can assume GCC, Clang, MSVC, or ICC.
At any rate: crazy hard, crazy fun problem. I'm sure LLMs have a role somewhere, but I'm not sure exactly where: the future will tell. My guess is some kind of "copilot" / "assistant" type role rather than directly making the decisions.
(If this is your kind of thing... I'll be writing more about it on my blog soonish...)
{kind=link}